The reason we study the relational model at all is because layers of abstraction makes for good software engineering. Making a database schema was a revolution in the early 70s because it separated the way your data was going to be laid out from the hardware or even software managing the data. The next step in our abstraction is to create diagrams that are even higher level explanations of our choices. This speeds up our layout, encourages better DB design, and helps communicate the notions to other stakeholders, future developers on the project and even yourself.
E-R stands for Entity-Relationship and it is both a model and a diagramming method (ERD are taught to finance majors so that we can communicate about business processes). Here's my take:
All of our tables fall roughly into two categories: Entities which are real-world objects with attributes, and relationships which are used to store associations between entities. For instance:
That diagram is an example of an E-R diagram and it has two entities: instructor and phone with one relationship: inst_phone. We can actually think out whether an instructor should only have one phone stored in the instructor's attributes or many phone numbers. The underlined attributes are keys for those entities.
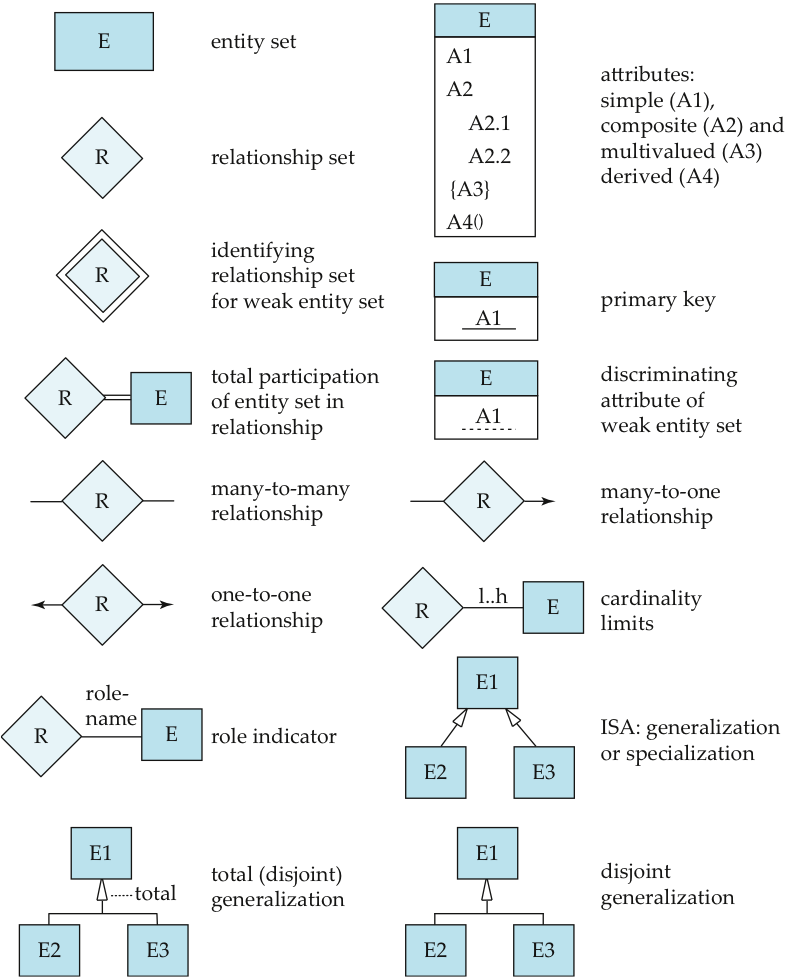
Here is a diagram with many of the main features of ERDs:
Here is a sample ERD for our university database:

Once we've talked out what these mean let's practice our own in the following scenarios (from the book):
An alternate representations:

The chart I embedded above was made with draw.io. I've also done ERDs using lucidcharts. For this part of the lecture, visit one of those sites and see if you can create an ERD online for one of the ERDs we did by hand previously.
I think that our book uses a blend of typical ERDs and UML. But you can load up a template chart with one of those buzzwords and enjoy dragging and dropping things. At first you'll be a bit slow but you can speed up over time.
So our tables (relations) are filled with rows (elements/instances) and we're getting pretty good at hacking at them with SQL. It is important that I be able to isolate any particular row. In some relation any set of attributes (columns) which can uniquely determine an element (row) is called a key. If I can remove some of those attributes and still uniquely identify the row then the key was a super key. If the key was minimal, in the sense that removing any column from the key would no longer uniquely identify rows then it is called a candidate key. A candidate key which has been chosen by the database designer to serve as the unique identifier for all rows is called the primary key.
You can declare a primary key when creating a table and from now on SQL will complain when you try to insert a row which has a duplicated primary key. Also bear in mind that your primary key can be multiple attributes, the uniqueness might require several columns to lock down.
Let's analyze some examples for the Schema Baseball Player(Last Name, First Name, Team, Number, SSN)
Last NameLast Name, First Name, TeamSSNTeam, NumberWe know from math that a function is something which gets a specified output for a specified input. Like \(f(x) = x^2\) is a function which maps \(1 \to 1\) and \(-9 \to 81\). Given that functions are really just relations and databases are really just super relations, we can ask what the version of a function is in a database schema too. Here goes some jargon: let \(r(R)\) be a relation on the attributes R (think of R as a set of columns).
For two subsets \(\alpha, \beta \subset R\) we say a relation \(r(R)\) satisfies the functional dependency \(\alpha \to \beta\) if for all pairs of tuples \(t_1\) and \(t_2\) in the instance such that \(t_1[\alpha] = t_2[\alpha]\), it is also the case that \(t_1[\beta] = t_2[\beta]\).
In human terms, a functional dependency is when the values in a row of some specified columns (\(\alpha\)) in a table are enough to predict the values in some other columns (\(\beta\)) of the same row.
To make a list of functional dependencies usually requires some understanding of the real world situation. Although you can state all of the functional dependencies at any given moment in a mechanical dry way, it is best to build these almost as business rules.
Here is a dump of the takes table in our university database, what dependencies can we spot? Do you think that (course, section)\(\to\)(semester, year) is a valid functional dependency? (How about at UD?)
00128|CS-101|1|Fall|2009|A
00128|CS-347|1|Fall|2009|A-
12345|CS-101|1|Fall|2009|C
12345|CS-190|2|Spring|2009|A
12345|CS-315|1|Spring|2010|A
12345|CS-347|1|Fall|2009|A
19991|HIS-351|1|Spring|2010|B
23121|FIN-201|1|Spring|2010|C+
44553|PHY-101|1|Fall|2009|B-
45678|CS-101|1|Fall|2009|F
45678|CS-101|1|Spring|2010|B+
45678|CS-319|1|Spring|2010|B
54321|CS-101|1|Fall|2009|A-
54321|CS-190|2|Spring|2009|B+
55739|MU-199|1|Spring|2010|A-
76543|CS-101|1|Fall|2009|A
76543|CS-319|2|Spring|2010|A
76653|EE-181|1|Spring|2009|C
98765|CS-101|1|Fall|2009|C-
98765|CS-315|1|Spring|2010|B
98988|BIO-101|1|Summer|2009|A
98988|BIO-301|1|Summer|2010|
Let's try to spot some functional dependencies in the Chinook Database.
In this new notation a super key is a subset \(K \subset R\) which gives a functional dependency \(K \to R\). While a candidate key is a minimal super key.
This is a deep topic that I'm afraid might not get the treatment it deserves in this lecture. If I feel it is short changed we'll come back to it Thursday.
The goal is to create databases which are not prone to internal consistency errors. If it is possible to update a value somewhere and cause a logical error in the database then you have made a poor design. This means that data shouldn't be hidden, shouldn't be duplicated, and shouldn't have hidden logical dependencies. To help define "Good" database design we have some rigorous standards which are codified as Normal Forms.
The normal forms are 1NF, 2NF, 3NF, BCNF, 4NF, 5NF, 6NF.
The mnemonic for the first three normal forms (which is usually good enough) is this: Every non-key attribute must provide a fact about the key, the whole key, and nothing but the key.
First Normal Form: your values should be atomic. That means you should not overload data into one attribute.
Here is an example of something not in 1NF:
| item_id | properties |
|---|---|
| 1 | metallic shiny pretty |
| 2 | dense ugly matte |
Here it is in 1NF
| item_id | properties |
|---|---|
| 1 | metallic |
| 1 | shiny |
| 1 | pretty |
| 2 | dense |
| 2 | ugly |
| 2 | matte |
Second Normal Form: No partial key dependencies. No subset of your candidate keys should uniquely identify a (different) subset of the row.
| SSN | LastName | FirstName | Phone Number | Phone Type |
|---|---|---|---|---|
| 111 | Smith | Joe | 123-4567 | Home |
| 222 | Davis | Jim | 666-6666 | Cell |
| 333 | Smith | Maggie | 123-4567 | Home |
| 111 | Smith | Joe | 555-5555 | Cell |
| 222 | Davis | Jim | 777-7777 | Home |
| 444 | Davis | Jim | 999-8888 | Cell |
In this case SSN \(\to\) (Last Name, First Name) and Phone Number \(\to\) (Phone Type) are functional dependencies. The only candidate key is (SSN, Phone Number). This table fails to have every column depend on the entire candidate key. In human terms, this table can be split up.
| SSN | LastName | FirstName |
|---|---|---|
| 111 | Smith | Joe |
| 222 | Davis | Jim |
| 333 | Smith | Maggie |
| 444 | Davis | Jim |
and
| Phone Number | Phone Type |
|---|---|
| 123-4567 | Home |
| 666-6666 | Cell |
| 555-5555 | Cell |
| 777-7777 | Home |
| 999-8888 | Cell |
This requires a relationship table:
| Phone Number | SSN |
|---|---|
| 123-4567 | 111 |
| 123-4567 | 333 |
| 666-6666 | 222 |
| 555-5555 | 111 |
| 777-7777 | 222 |
| 999-8888 | 444 |
Third Normal Form: All of my attributes should not be identifiable by non-key attributes.
So here is an example of a candidate key which predicts a column but another column which is predicted by a non-key column:
| Song-ID | Genre-ID | Genre-name | Song-name | Price |
|---|---|---|---|---|
| 1 | 1 | Blues | Kind of Blue | 1.99 |
| 2 | 1 | Blues | Freddie Freeloader | 1.99 |
| 3 | 2 | EDM | We can make the world stop | .99 |
In this case Song-ID is a candidate key, but Genre-name is a functional dependency of Genre-ID.
Let's split:
| Song-ID | Genre-ID | Song-name | Price |
|---|---|---|---|
| 1 | 1 | Kind of Blue | 1.99 |
| 2 | 1 | Freddie Freeloader | 1.99 |
| 3 | 2 | We can make the world stop | .99 |
| Genre-ID | Genre-name |
|---|---|
| 1 | Blues |
| 2 | EDM |
Analyze this table and make some recommendations:
| Party-Time | Party-Location | Perpetrator | Perpetrator's Birthday |
|---|---|---|---|
| 2015-06-18T20:00 | E Mill Dr. | Taylor | 09/22/1993 |
| 2015-06-12T18:00 | Cleveland Ave. | Simone | 07/03/2013 |
| 2015-05-31T13:00 | S. College Ave. | Jimmy | 01/30/1974 |
Here is a real life row from a (humble) hello-world un-normalized database. Can you make a normalized schema from it?
20121226181047_|{"prefix":"20121226181047_","numPics":16,"photoLoadedTime":"2012-12-26_16:40",
"status":"setAside","metaDescription":"","metaWidth":"2.5","metaHeight":"5.75","metaDepth":"0",
"cost":"0","extraInfo":"This item weighs .01 lbs. It measures 2.5 x 5.75 x 0. Someone
thinks this item is NOT asian.","metaWeight":".01","inventoryPrefix":"20121226181047_",
"source":"pookDec14","anthonyLee":"off"}