Now that we know about candidate keys it's time to think about how long a look up takes.
Let's say I want to look up a student by student_id in a university database. As a developer I just plop in some SQL, but as a business person I care about the speed of the response. Seconds and minutes spent in repetitive task add to many dollars paid out. So I want to think about how many steps the database takes to find the record. In the worst case it has to check every row in the student table to find a row which matches student_id.
As developers if we know that this is a common use case we can speed up the query by creating an index. An index for a database acts just like the index at the back of a book. It gives you a quick way to lookup a keyword and the page to jump to in the book. Because the index is sorted (and the page numbers are sorted) this is a logarithmic time process.
To create an index we use the SQL command:
CREATE INDEX index_name_here ON table_name_here (column1, column2, ...)
In MySQL we can use the query EXPLAIN query_here to get a report on what steps the database took to find the record you have requested. In SQLite3 the command is EXPLAIN QUERY PLAN query_here. Let's create a larger version of the university database and test it.
Fire up a terminal and wget DDL.sql for sqlite or DDL-no-fk.sql for MySQL and largeRelationsInsertFile.sql and create the DB using the DDL file and populate it using the largeRelations File. Or just grab the biguni.db sqlite database directly from me. Feel free to choose MySQL using our EE/CIS workflow too.
WARNING: DO NOT DO select * from table; Please add a LIMIT clause to your queries.
Task 1: How many rows did your DBMS need for select * from takes where ID="65901";
Task 2: How many rows did your DBMS need for select * from takes where course_id="237";
Task 3: Use an index to fix the problem case.
Task 4: Now how many rows are examined?
Task 5: Create a dual index using (year, semester)
Task 6: Compare select * from takes where year in (2010, 2009, 2008) and semester ="Fall"; with select * from takes where semester ="Fall";
I really encourage you to visit Use the index, Luke an online book walking through practical SQL speed optimizations for developers. Read it this weekend, your future-self will thank you. Hell, you might even do so well at life because of it that your future self can afford a time-machine and they'll thank you this weekend. Or the future won't have any SQL in it, in which case you'll want to save your questions (about your own future) until we do MongoDB and Firebase.
If you find that your data-driven application has complex tasks to do, which are long-running. You might want to consider caching the results in some static way for fast retrieval later. No assignment for this, just a concept that you might want to consider in your future work.
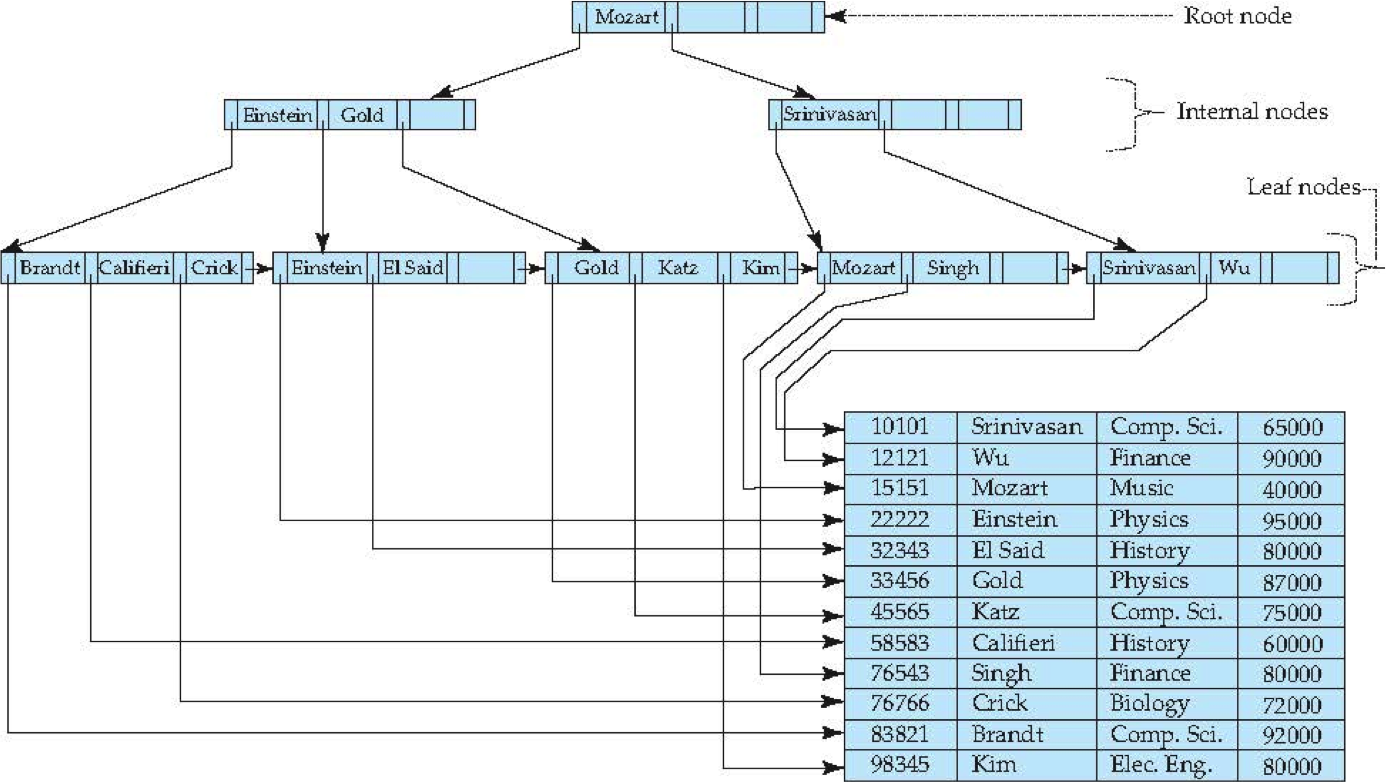
So for an index to do its magic it must be able to quickly find rows attached to specific values, and it should be able to add new rows without moving millions of other rows. The key is using a B+Tree, which is a data-structure built up from two classics: A search tree and a linked-list. The Leaf nodes will be the links in the linked-list and the nodes of the search tree will have some keys and pointers to help navigate. Here is a sample diagram:
So when we create an index we are firing up a new B+Tree for that index. When we add or delete a row then the DBMS has to update the index too. The search tree stays balanced and has roughly logarithmic height. If you have an available index then you can use it to get to the row quickly. If not then you might end up traversing the linked list looking for your search criteria.
The upshot is the following: the more indices you have the more costly your updates AND you should carefully analyze the ways that your data is accessed most often and optimize for those cases. This requires some domain knowledge and a developer's insights.
Here is a B+Tree simulator. Click it. Grow it.
Now that we've started to learn about analyzing the speed of our queries and methods we can use to improve SQL performance, we should address some other concerns of mine.
Your business applications will have what I call domain logic, weird business rules that are related to the "domain" that your app supports. I'll give you a sample case from my antiques company.
Task A: Read this situation, think about it, and discuss some solutions:
We sell antiques that we buy but also antiques that people ask us to sell for them. Our consignment rates are somewhat intricate, there is a default rate of 50/50 for items selling less than $100 a 65/35 split (in the consignor's favor) for items selling over $400 and a steady walk from 50/50 to 65/35 between the two prices. Then certain items will get a special rate, like 70/30 by $250, or a flat rate of 75% if it's a fantastic item.
So here are some business questions emerging from these truths:
You all will have similar situations to decide with your Six Degrees of Kevin Bacon project. In general it is wise to think about your domain logic in an object oriented way, but you still have some tough choices when it comes to matching your classes to your normalized database tables.
The first project that you all did had most of the logic in a few key functions. This architecture can be described as a transaction script model. In this way whenever a database action is needed a script or simple function is called and the job is done that way. As projects become complex or require extensibility this method breaks down.
The other two models I'll share with you are called active record and obect-relational mappings. In an active-record model your database tables are as close as possible to real domain classes, and each row might be an instantiation of that class. Then the object has some methods like save() and fetch() that load it with data or persist that data.
Using an Active-Record architecture is one of the best reasons for making a VIEW. Recall that since all of our queries are tables we can create virtual tables using something like:
CREATE VIEW view-name AS select-query-here;
So active record is a specific type of Object-Relation Mapping, which is a more general idea for a general adapter from domain classes to databases. Key concept: if you use ORM in the right way you can switch out your database without impacting your business logic.
The difference with Active Record is that active record is a more monolithic design, where tables and classes are almost the same, but the classes have methods. A general ORM allows your classes to live as they see fit and use the mapping to talk to the database when it's needed.
If I had time I would give a set of useful ORMs in PHP and Node here. If I find that time I'll do so. If not, please google search around with these new buzzwords.
Task ZZ: Create the simplest version of a squirrel war game that you can think of. What are the classes that you need, methods, what logic?
Task ZA: How would you make your classes persist to a simple database?
Task Great: Can we create this game in Node or PHP?
Imagine your design using transaction scripts, active record, and an ORM. How are they different for your game?